背景
Apache Beam 是Google 开源的一个统一编程框架,它本身不是一个流式处理平台,而是提供了统一的编程模型,帮助用户创建自己的数据处理流水线,实现可以运行在任意执行引擎之上批处理和流式处理任务。它包含:
- 一个可以涵盖批处理和流处理的统一编程模型
- Beam SDK,支持 Java 和 Python
- 一系列Runner(可以理解为“适配器”吧),让其编程模型运行在不同底层处理引擎(Google Cloud Dataflow,Spark,Flink等)
Beam (模型)能为用户带来什么价值?
这里使用一个例子简单地介绍 Beam的能力。在此之前先介绍了流数据处理的两个基本概念:
- 事件时间(Event Time):事件产生的时间
- 处理时间(Processing Time):事件(数据)到达处理系统的时间
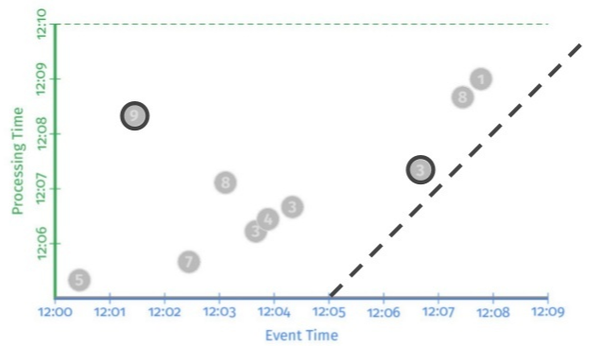
上图中,横轴表示的是事件时间(从12:00开始),纵轴表示的是处理时间(从12:05开始),虚线表示的是一种理想的情况,即事件时间与处理时间相同,也就是说事件一产生就直接被系统接收到并处理(注:由于纵轴的时间是从12:05开始,所以此处虚线是从事件时间12:05的位置开始画出)。
图上面的灰色圆点表示的是一系列事件,他们只能出现在虚线的左上方(因为必须满足:时间事件小于处理时间,也就是事件总是先产生然后才被系统接收处理)。我们看到标号为“3”的点与虚线的水平距离很近,也就是说此事件一产生就被系统接收到进行处理,延时较小;反之,编号为“9”的圆点,它所代表的事件在12:01~12:02直接产生,但是到了 12:08之后才被处理,延时较大。
明白了以上两个概念,接下来通过四个动画来回答四个问题,我们可以较好地了解 Beam 编程模型的能力:
做什么计算?(What result are calculated?)
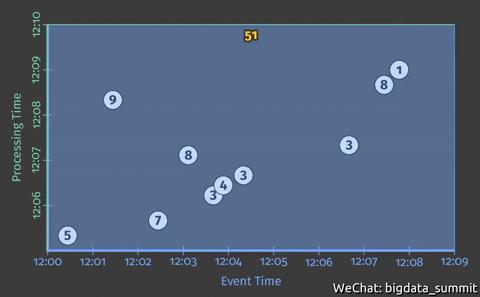
拿 sum (累加事件的某个指标,如上图灰色圆点的整数值)为例,如下图所示,在某个时刻(如12:10)计算出之前所接收到的整数的和,这是一个典型的批处理的场景。
注:以下所有动画中的累加数字,白色表示计算的中间结果,黄色表示返回的计算结果,才是用户可见的。
相应的 Beam 代码如下图所示

当然,做到这一步还看不出 Beam 的特殊能力,从下面一个问题开始,才开始显现 Beam 模型的价值
数据在什么范围中计算?(Where in event time are results calculated?)
就是在代表事件时间的横轴坐标上,对落在哪个区间的灰色圆点施加计算呢?
假如我们现在想在事件时间横轴上统计每个2分钟时间窗口的整数累加值,即完成如下图动画所示的效果:
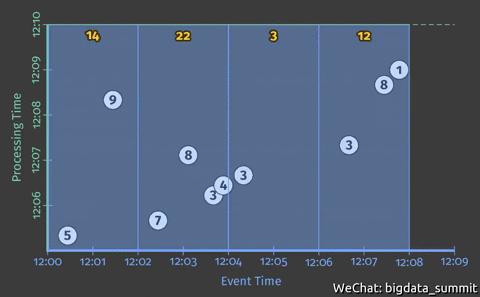
对有些计算框架来说,这就开始有些棘手了。但是有了 Beam,下面寥寥几行代码就可以实现(新增的代码为蓝色部分):

Beam 自动为每个时间窗口创建一个小的批处理作业,在处理时间纵轴 12:10 的时候触发计算。但是这样,我们只能等到最后的一个时间点(12:10)才能得到计算结果。如果我们想在更早的时间点得到时间窗口的统计结果(这个问题就开始变得复杂了),我们开始需要考虑如何回答下一个问题。
何时将计算结果输出?(When in processing time are result materialized?)
就是在代表处理时间的纵轴坐标上,在什么时间点返回计算结果?
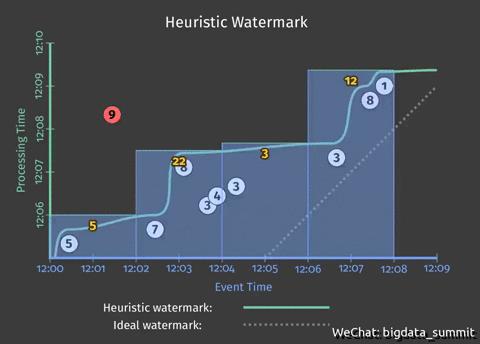
为了回答这个问题,我们首先要回答,对于事件时间横轴上的每个时间窗口,在处理时间纵轴上的哪个位置,待统计的数据/事件(也就是图中的圆点)都被接收到了?这就涉及到一个叫做水位线(watermark)的概念,它的作用就是来回答我们这个问题的。在下图动画中的曲线就是一条 水位线,它可以根据某些指标(比如历史数据等)推测出来(但不一定完全准确)。这样,我们就可以不必等到最后的时间点才能得到各个时间窗口的统计结果,具体效果如下图动画所示:
新增的 Beam 代码如下图绿色部分所示:

比如对于第一个时间窗口而言,水位线的预测存在偏差,因为标号为“9”的数据落在这条曲线之上,也就是在 watermark 预测的处理时间点(12:06左右)时还未被系统接收到。这就涉及到下一个问题。
迟到数据如何处理?(How do refinement of result related?)
就是在接收到延迟到达的数据后,如何对之前的计算结果进行修正?
通过对上面的代码稍加修改(如下图所示,绿色和红色部分)

我们可以得到如下动画展示的效果:
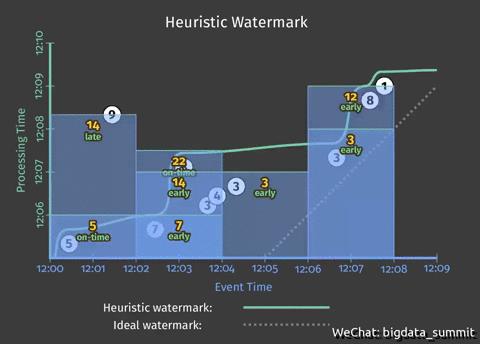
从中我们可以看到:
动画中标识为“early”的结果为探测性结果 ,因为根据 watermark预测,后续还有可能继续接收到这个时间窗口的数据
动画中标识为“on-time”的结果为(及时/普通)结果, 因为根据 watermark 预测,后续不再会接收到此时间窗口的数据
动画中标识为“late”的结果为延迟结果,这种情况表示有数据延迟到达,也就是 watermark 的预测出现偏差,需要对结果进行校正,这里采用的校正方式就是累加更新结果
可以看到,利用 Beam 的模型,我们不需要编写复杂的逻辑,就可以灵活地/优雅地处理流处理计算过程中出现的一些棘手场景。